How Neural Networks Recognize Speech-to-Text

Founder & CEO at Azoft
Reading time:
Gartner experts say that by 2020, businesses will automate conversations with their customers. According to statistics, companies lost up to 30% of incoming calls because call center employees either missed calls or didn’t have enough competence to communicate effectively.
To quickly and efficiently process incoming requests, modern businesses use chatbots. Conversational AI assistants are replacing standard chatbots and IVR. They are especially in demand among B2C companies. They use websites and mobile apps to stay competitive. Convolutional neural networks are trained to recognize human speech and automate call processing. They help to keep in touch with customers 24/7 and simplify the typical request processing.
There is no doubt that in the future call centers will become independent from operator qualification. Speech synthesis and recognition technologies will be a reliable support for them.
Our R&D department is interested in these technologies and has conducted new research at the client’s request. They trained neural networks to recognize a set of 14 voice commands. Learned commands can be used to robocall. Keep reading to learn about the results of the study and how they can help businesses.
Why Businesses Should Consider Speech-to-text Recognition
Speech recognition technologies are already used in mobile applications — for example, in Amazon Alexa or Google Now. Smart voice systems make apps more user-friendly as it takes less time to speak rather than type. Beyond that, voice input frees hands up.
Speech-to-text technologies solve many business issues. For instance, they can:
- automate call processing when customers want to get a consultation, place or cancel an order, or participate in a survey,
- support Smart Home system management interface, electronic robots and household device interfaces,
- provide voice input in computer games and apps, as well as voice-controlled cars,
- allow people with disabilities to access social services,
- transfer money by voice commands.
Call centers have become the “ears” of business. To make these “ears” work automatically, R&D engineers train bots using machine learning.
Azoft’s R&D department has concrete and practical expertise in solving transfer learning tasks. We’ve written multiple articles on:
- face recognition technology in photo and video,
- object detection in images using convolutional neural networks.
This time, our R&D department trained a convolutional neural network to recognize speech commands and to study how neural networks can help in dealing with speech-to-text tasks.
How Neural Networks Recognize Audio Signals
The new project’s goal is to create a model to correctly identify a word spoken by a human. To get a final model, we taught neural networks on a body of data and tailored to the target data. This method helps when you don’t have access to a large sample of target data.
As part of a study, we:
- studied the features of signal processing by a neural network
- preprocessed and identified the attributes that would help to recognize words from a voice recording (these attributes are on the input, and the word is on the output)
- researched on how to apply convolutional networks in a speech-to-text task
- adapted the convolutional network to recognize speech
- tested the model in streaming recognition
How We Taught Neural Networks to Recognize Incoming Audio Signals
For the research, we used an audio signal in the wav format, in 16-bit quantization at a sampling frequency of 16 Khz. We took a second as a standard of duration. Each entry contained one word. We used 14 simple words: zero, one, two, three, four, five, six, seven, eight, nine, ten, yes, and no.
Attribute Extraction
The initial representation of the sound stream is not easy to perceive as it looks like a sequence of numbers in time. This is why we used spectral representation. It allowed us to decompose sound waves of different frequencies and find out which waves from the original sound formed it, and what features they had. Taking into account the logarithmic dependence of how humans perceive frequencies, we used small-frequency spectral coefficients.
The process of extracting spectral attributes
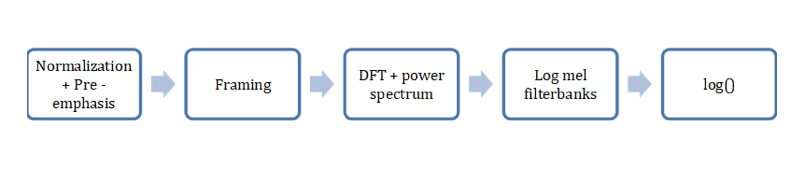

- Pre-emphasis
Signals differ in volume level. To bring audio in one form, we standardized and used a high-pass filter to reduce noise. Pre-emphasis is a filter for speech recognition tasks. It amplifies high frequencies, which increases noise resistance and provides more information to the acoustic model.
- Framing
The original signal is not stationary. It’s divided into small gaps (frames) that overlap each other and are considered stationary. We applied the Hann window function to smooth the ends of the frames to zero. In our study, we used 30 ms frames with an overlap of 15 ms.
- Short-time Discrete Fourier Transform
The Fourier transform allows you to decompose the original stationary signal into a set of harmonics of different frequencies and amplitudes. We apply this operation to the frame and get its frequency representation. Applying the Fourier transform to all the frames forms a spectral representation. Then, we calculate the spectrum power. The spectrum power is equal to half the square of the spectrum.
- Log mel filterbank
According to scientific studies, a human recognizes low frequencies better than the higher ones, and the dependence of his/her perception is logarithmic. For this reason, we applied a convolution of N-triangular filters with 1 in the center (Image 2). As the filter increases, the center shifts in frequency and increases logarithmically at the base. This allowed us to capture more information in the lower frequencies and compress the performance of high frequencies of the frame.
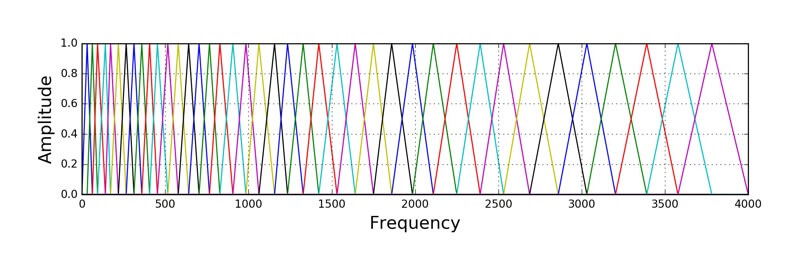
The Choice of Architecture
We used a convolutional neural network as a basic architecture. It was the most suitable model for this task. A CNN analyzes spatial dependencies in an image through a two-dimensional convolution operation. The neural network analyzes nonstationary signals and identifies important criteria in the time and frequency domains.
We applied the tensor n x k, where n is the number of frequencies, and k is the number of time samples. Because n is usually not equal to k, we use rectangular filters.
The Model’s Architecture
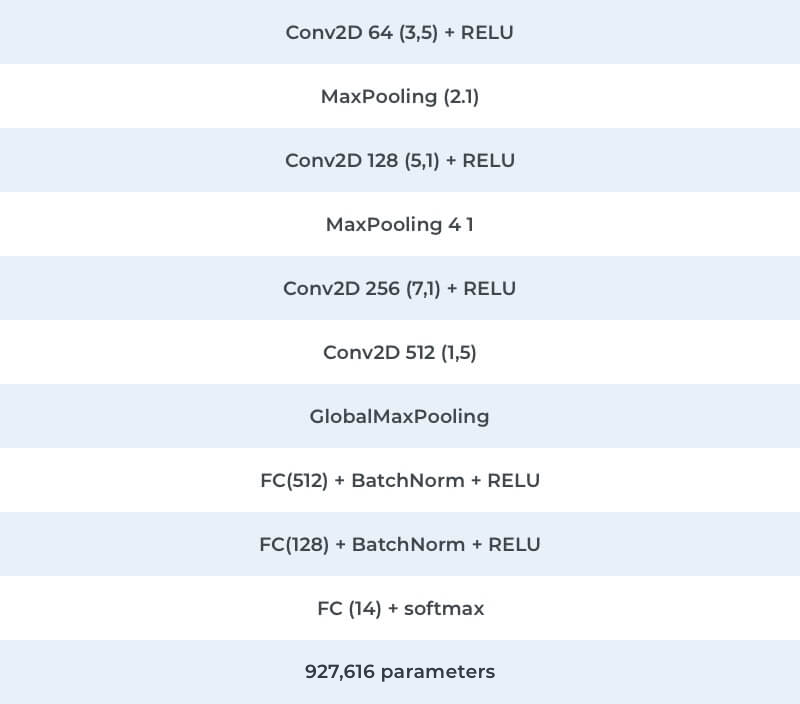
We adapted the standard convolutional network architecture to process the spectral representation of the signal. In addition to two-dimensional filters on the first layer, which distinguished common time-frequency features, one-dimensional filters were used.
To bring this idea to fruition, we had to separate the processes of identifying frequency and time criteria. To accomplish this, the second and third layers were made to contain sets of one-dimensional filters in the frequency domain. The next layer extracted time attributes. Global Max Pooling allowed us to compress the resulting attributes map into a single attribute vector.
Data Preparation Before the Training
The keyword set consists of 13 commands in Russian: да (yes), нет (no), 0,…, 10. There were a total of 485 records at a sample rate of 44kHz.
Non-keywords are a set of non-targeted words that cannot be recognized. We used English words from Google and inverted records from the dataset. The ratio of these to the full data set is 15%.
Silence class is the recordings that are not related to human speech. For example, ambient sounds (city, office, nature, interference, white noise). We used a simplified model for VAD task based on convolutional networks. We taught it to separate two classes: speech and no-speech. We used data from Google as speech data and background noise as well as manually recorded noise from an office, street, and urban environment as non-speech.
To improve the noise immunity of the model and expand the data model, we used the following augmentation methods:
- Speed Tune
- Pitch Shift
- Add Noise
The set of noise records consists of 10 records per category:
- OfficeHome
- Urban environment
- Suburban environment
- Interference
After adding noise, we obtained a weighted sum of the recording and random noise parts. Then, after augmentation, the sampling rate was reduced to 16 KHz. We assume that the result will be more realistic with more detailed recordings. We performed the conversion operations and obtained 137448 objects from 485 records.
Model Preparation
We used transfer learning to improve the quality of the model. The chosen architecture was trained on a large data package — a dataset from Google of 65,000 one-second records for 30 commands in English.
Learning and Testing Results
The training sample included 137488 objects and the testing sample had 250 objects. For the testing sample, we took speakers’ recordings that were not included in the training sample. We trained the neural network using the Adam optimization method in three variations:
- model training from scratch (Fresh)
- convolutional layer freezing in a pre-trained model (Frozen)
- retraining a pre-trained model without freezing (Pre-Trained)
“Fresh” was carried out in seven stages and “Frozen” and “Pre-trained” in three stages. Check out the results in the table below.
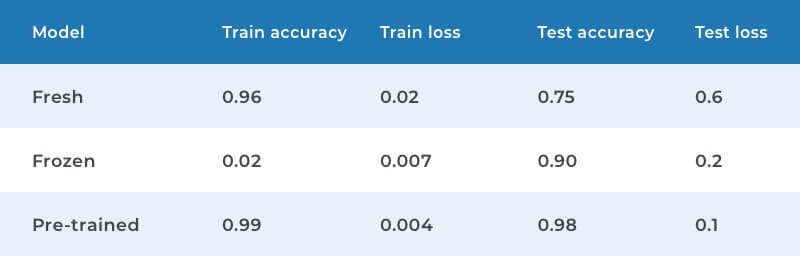
As a result, we chose to use a pre-trained neural network on a large data package with fine-tuning and without freezing convolutional layers. This model adapts better to the new data.
Stream Test
The model was also tested live. The speaker pronounced words in the microphone, and the network produced the result. We didn’t use the speaker’s voice in the training sample. This allowed us to check the quality of unknown data. The sound was read every quarter second, the cached second was updated, and the model classified it. To avoid neural network mistakes, we used a confidence threshold.
Test device characteristics:
- CPU: Intel Core i7 7700HQ 2.8 GHz
- RAM: 16 Gb
Test characteristics:
- Incoming audio stream refresh rate: 0.25 sec
- Number of channels: 1
- Sampling rate: 16 KHz
- Incoming stream: 4000 by 16 bytes
Recognition speed:
- Silence speech: 0.23 sec
- Activity speech: 0.38 sec
Stream Test Results
The model recognized individual commands from the target dataset well but could give false answers to words that sound similar to the commands from the dataset. In continuous speech, consisting of many words, the quality of the processing of audio signals dropped significantly.
Conclusion
We examined the recognition of commands from the speech stream and revealed that:
- Transfer learning can be very helpful when there is not a large body of data. Preprocessing and methods of representing audio signals are important in the recognition of commands.
- Noise makes it difficult to recognize audio.
- A similar speech recognition technology can be applied with the well-known small dictionary of commands.
- To train a neural network, quality data is needed.
Businesses are interested in neural network signal recognition as it helps to build communication with Generation Zero. They use messages as their main method to communicate with friends, consume content, and explore products.
Signal recognition by neural networks has already sparked great interest among businesses as a way to establish communication with “generation zero”. This audience uses messages as the main means of communicating with friends, viewing content and exploring products. The purchasing power of “generation zero” is 200 billion dollars a year. A number which is expected to increase in the future.
Chatbot developers take into account the perspectives of millennials: today users easily make orders with instant messengers like Facebook, WhatsApp, Viber, Slack, and Telegram. According to researchers, 80% of companies will increase the number of their customer self-services in 2 years. Audio recognition systems will be a useful feature.
Our team will continue studying this topic. We will study new learning models that can improve speech-to-text recognition using neural networks.


Comments