Machine Learning Methods for Image Labeling and Annotations

Founder & CEO at Azoft
Reading time:
Introduction
Video and photo processing is an urgent and challenging task in computer science. Every owner of a mobile phone is a potential author of a video. As a result, the great stream of user-generated content requires an organized system of classification to help find the right videos.
One way to handle video classification is by using tags annotation. Tagging has proven itself very useful: anyone who has ever used search by tags knows that they are simple and effective. However, to add tags, a person needs to view the whole video at least once, which takes the most valuable resource — time. Our team decided to automate the tagging process using machine learning image labeling.
Task
To create an application with a web interface that downloads videos from your computer or via a web link analyzes the content, and provides a list of tags.
Project Overview / How it works
Video files often contain two components: video stream and audio stream. At the moment, we are working with the video stream only.
Video processing takes place in several steps:
- Upload videos from computer or via youtube.com link
- Split the video into individual frames
- Classify images taken from the video
- Collect statistics
- Show tags
Splitting Video Into Frames
You should split the original video into separate frames to process it. To improve performance, we capture every tenth frame. Reduce its width to 320 pixels, the height is reduced proportionally.
In the future, our team is planning to implement a more intelligent frame capture algorithm. For example, searching for keyframes between the significant changes in scenes.
Image Classification
To assess the quality of the classification algorithm, we need to compare the results of its work with experts’ estimates. If the results fully match, the algorithm is considered ideal, as well as the system that is based on the algorithm. In practice, different algorithms may or may not be close to ideal, with varying degrees of “closeness” to ideal. To estimate these degrees we use metrics — the numerical characteristics obtained by analyzing the results of both our system’s work and the experts’ work for the same collection of images.
All images can be classified as relevant or not relevant using the relevance criterion, and also as retrieved or not retrieved. The classification matrix, in this case, would look like this:

1. Recall
Recall is defined as the ratio of relevant images retrieved to the total number of relevant images:

2. Precision
Precision is calculated as the ratio of relevant images retrieved to the total number of outputted images:

Precision describes the system’s ability to retrieve only the relevant images in the results list but does not account for the number of relevant images that the system missed. Precision, as well as recall, cannot be used as the sole criterion for the search quality. Typically, they are used together.
In practice, precision and recall are usually inversely proportional to each other. In other words, you can increase the precision of classification so that the probability of error is minimized, but the number of missed images of this type will also increase. Alternatively, you can increase the recall, then the number of missed shots will decrease, but the likelihood of errors will increase.
Our goal is to achieve maximum precision and recall. To solve this problem, we decided to use many different classifiers. Acting independently, they significantly increase the recall, while slightly affecting precision.
Our images classifier should be able to recognize objects in different categories. During the recognition process, the system defines different levels of the object’s localization.
1. The object is present in the image. Image classification

2. Location of the object is known. Object detection and localization
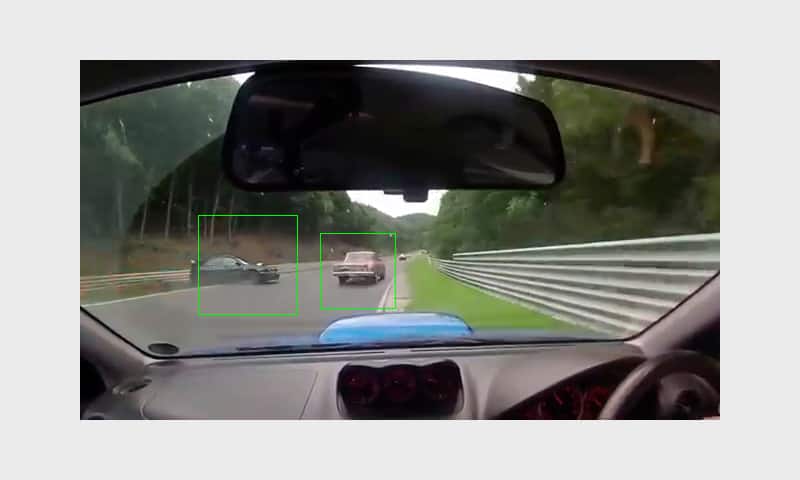
For our application, we use both levels of localization.
1. Object Category Definition
The challenge of object category definition is usually solved by the following scheme:
- Presentation of images in the form of feature vectors
- Training and use of the classifier with feature vectors.
To represent an image as a feature vector, the following features can be used:
- Histograms of color
- Histograms gradients (gradient direction histogram, HOG (Histogram of Oriented Gradients), SIFT)
- Incidence matrix
- Visual words.
The following methods can be used to train the classifier:
- Nearest neighbor algorithm
- Support Vector Machines, (SVM)
- Neural networks
- Markov random fields.
Also, the object category definition challenge can be solved by the methods of deep learning, such as convolutional neural networks.
Currently, we are using bags of visual words plus support vector machine method. Let’s take a closer look at these methods.
The basic idea of classification by visual words:
1. A set of images is divided into categories.

2. Feature detection: a set of characteristic features is extracted from each category, or the image is divided using a grid.
3. From these extracted feature fragments the system creates feature vectors.
4. These vectors are split into clusters via k-means method. The clusters are compact and separated from each other.
5. Each cluster is a visual word.

6. For each category, we obtain a histogram of visual words.
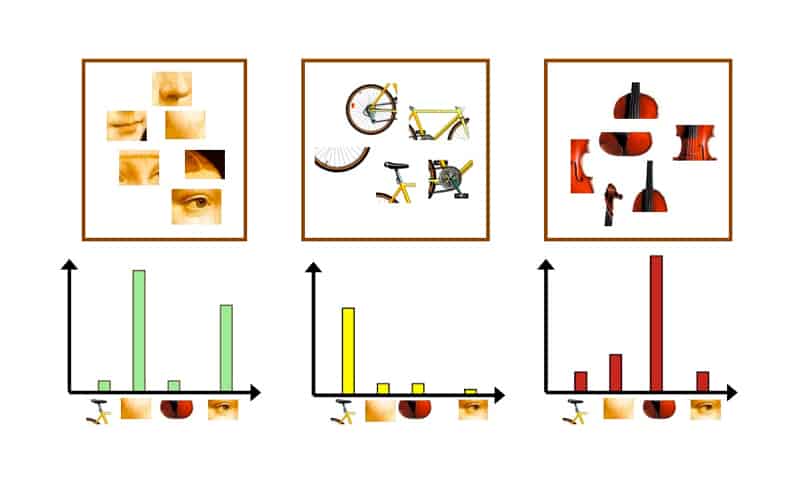
7. The system creates vectors from the obtained histograms. SVM classifier is based on these vectors.

8. For each category, bags of visual words are created.


2. Object Detection and Localization
The challenge of object detection and localization in the image is usually solved by the following scheme:
- The image is divided into fragments (method of the sliding window with a different scale is the most commonly used).
- We train and run a classifier using feature vectors, given their spatial arrangement (i.e., the relative position of features to each other).
We can use the same features for image detection as those used for determining the object category, but it is necessary to take into account the spatial location characteristics relative to each other.
Popular algorithms and methods of obtaining features are:
- Viola-Jones object detection
- Local Binary Patterns, LBP
- Histogram of Oriented gradient, HOG
In addition, deep learning can be used for object detection and localization.
For our app, we use the Viola-Jones method because it gives the most accurate results in a larger recall, as opposed to other methods (LBP, HOG).
The Viola-Jones object detection uses Haar basis functions.

There’s a simple and intuitive visualization of working Haar-Cascade Classifier:
Implementation
Our team first began the process of video frame classification using the Haar-Cascade Classifier. You can find the following classifiers in open access:
- 5 classifiers for human en face
- 2 classifiers for human profile
- 2 classifiers for cat muzzles
- 1 classifier for cars
- 1 classifier for mechanical clock
We included these classifiers into our project and began testing. Initially, there were many false positives.

We significantly increased the precision of the system, as a result, reduced the number of errors. However, this resulted in that real cars became very difficult for the system to identify. For instance, in some videos that were exclusively devoted to cars, the system did not recognize any. With the cats the situation was similar.
Human face classifiers have shown satisfactory results both in terms of precision and recall thanks to their popularity and availability. Mechanical watch classifier virtually stopped recognizing watches, while the number of false positives was almost the same. Therefore, we decided to stop using it.
We also tried to introduce classifiers based on local binary patterns, LBP. However, they showed poor results for our task.
In extra modules of OpenCV 3.0, there is an ability to define text on the image. We decided that “text” as an additional category could be useful for us.
Having implemented the ability to define text on the image, we then tested it, set the precision thresholds, and obtained satisfying results.


Hereafter, the team moved on to work with SVM classifiers. The project uses standard OpenCV classifiers, trained on the VOC 2007 dataset.
- Airplane
- Bicycle
- Bird
- Boat
- Bottle
- Bus
- Car
- Cat
- Chair
- Cow
- Dining table
- Dog
- Horse
- Motorbike
- Person
- Potted plant
- Sheep
- Sofa
- TV/monitor
Bicycle, car, bike, and person classifiers have shown satisfying results. TV monitor was only detected if the monitor was turned off. Our project now includes classifiers for cars and people.
SVM classifier showed significantly greater recall than Haar basis functions classifier. Approximately 2-3 times more for people than seven Haar classifiers trained on the faces. While Haar classifiers only recognize faces, the SVM classifier detects faces, torsos (even from the back), and people in full height that are far away. Moreover, SVM classifier works even in cartoon films.



However, there are rare false positives, some of which are difficult to explain.

At the same time, SVM classifier is several times less productive than Haar classifiers. This being said, we still chose it for the detection of people because of the best recall/precision ratio.
Haar classifier recall for cars is very low, triggering occurs with good contrast and on the front/rear of the vehicle only.

SVM classifier recall is ten times higher. Until now, testing it, we haven’t found any false positives. Therefore, we only use SVM classifier for cars in our app.

SVM classifier for cats showed unsatisfying results. Therefore, we detect cats on video frames using Haar classifiers. The precision is high, but the recall remains low. This can be explained by the fact that cats have little common features: color patterns and face proportions are very different from one cat to another.

After processing the video, the system analyzes the statistics of activations. If they are very rare, they could be false positives. In this case, the corresponding tag is not displayed.
Implementation Difficulties and Current Status
While implementing the project, we faced the following challenges:
- Lack of stability of classifiers in open access
- Classification of video frames is a very resource-intensive process
- Precision threshold selection is very time consuming
- False positives may lead to errors in tags
At the moment, our application is running on a server with Intel Core processor i7-5820K 3.3GHz 15Mb Socket 2011-3 OEM (6 cores) and processes the video streams simultaneously in 12 threads. The app retrieves the following tags: people, cats, cars, text. Tagging is approximately 3 times faster than viewing the entire video, and precision thresholds are calibrated according to errors occured.
Conclusions
The project is not easy, but at the same time, it is very interesting and multifaceted. Our app has broad prospects for application and further development.
Azoft R&D experts have offered some interesting ideas for developing the app’s functionality: music recognition alike Shazam service, text recognition (if a word is often found on video, for example, BBC, BAR, RT, it is displayed as a tag). We also plan to add classifiers to the world-famous brand logos, such as Apple, Coca-Cola, Adidas, or train SVM classifiers on new data sets.
It may also be effective to train Haar classifiers on more specific features. For example, a white cat, a gray cat, a black cat, an orange cat, a striped cat. This way, the labeling recall increases, practically without affecting precision. To achieve these objectives, we plan on using convolutional neural networks, since this architecture is best suited for image recognition and analysis.


Comments